完成了网络请求和响应,如果响应头中Content-Type的值是text/html,那么接下来就是浏览器的解析和渲染工作了。
首先来介绍解析部分,主要分为以下几个步骤:
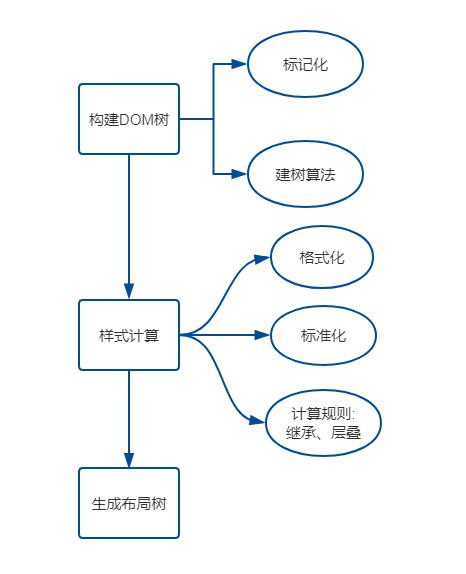
- 构建
DOM树 样式计算- 生成
布局树(Layout Tree)
# 构建 DOM 树
由于浏览器无法直接理解HTML字符串,因此将这一系列的字节流转换为一种有意义并且方便操作的数据结构,这种数据结构就是DOM树。DOM树本质上是一个以document为根节点的多叉树。
那通过什么样的方式来进行解析呢?
# HTML文法的本质
首先,我们应该清楚把握一点: HTML 的文法并不是上下文无关文法。
这里,有必要讨论一下什么是上下文无关文法。
在计算机科学的编译原理学科中,有非常明确的定义:
若一个形式文法G = (N, Σ, P, S) 的产生式规则都取如下的形式:V->w,则叫上下文无关语法。其中 V∈N ,w∈(N∪Σ)* 。
其中把 G = (N, Σ, P, S) 中各个参量的意义解释一下:
- N 是非终结符(顾名思义,就是说最后一个符号不是它, 下面同理)集合。
- Σ 是终结符集合。
- P 是开始符,它必须属于 N ,也就是非终结符。
- S 就是不同的产生式的集合。如 S -> aSb 等等。
通俗一点讲,上下文无关的文法就是说这个文法中所有产生式的左边都是一个非终结符。
看到这里,如果还有一点懵圈,我举个例子你就明白了。
比如:
A -> B
这个文法中,每个产生式左边都会有一个非终结符,这就是上下文无关的文法。在这种情况下,xBy一定是可以规约出xAy的。
我们下面看看看一个反例:
aA -> B
Aa -> B
2
这种情况就是不是上下文无关的文法,当遇到B的时候,我们不知道到底能不能规约出A,取决于左边或者右边是否有a存在,也就是说和上下文有关。
关于它为什么是非上下文无关文法,首先需要让大家注意的是,规范的 HTML 语法,是符合上下文无关文法的,能够体现它非上下文无关的是不标准的语法。在此我仅举一个反例即可证明。
比如解析器扫描到form标签的时候,上下文无关文法的处理方式是直接创建对应 form 的 DOM 对象,而真实的 HTML5 场景中却不是这样,解析器会查看 form 的上下文,如果这个 form 标签的父标签也是 form, 那么直接跳过当前的 form 标签,否则才创建 DOM 对象。
常规的编程语言都是上下文无关的,而HTML却相反,也正是它非上下文无关的特性,决定了HTML Parser并不能使用常规编程语言的解析器来完成,需要另辟蹊径。
# 解析算法
HTML5 规范详细地介绍了解析算法。这个算法分为两个阶段:
- 标记化。
- 建树。
对应的两个过程就是词法分析和语法分析。
# 标记化算法
这个算法输入为HTML文本,输出为HTML标记,也成为标记生成器。其中运用有限自动状态机来完成。即在当当前状态下,接收一个或多个字符,就会更新到下一个状态。
<html>
<body>
Hello sanyuan
</body>
</html>
2
3
4
5
通过一个简单的例子来演示一下标记化的过程。
遇到<, 状态为标记打开。
接收[a-z]的字符,会进入标记名称状态。
这个状态一直保持,直到遇到>,表示标记名称记录完成,这时候变为数据状态。
接下来遇到body标签做同样的处理。
这个时候html和body的标记都记录好了。
现在来到<body>中的>,进入数据状态,之后保持这样状态接收后面的字符hello sanyuan。
接着接收 </body> 中的<,回到标记打开, 接收下一个/后,这时候会创建一个end tag的token。
随后进入标记名称状态, 遇到>回到数据状态。
接着以同样的样式处理 </body>。
# 建树算法
之前提到过,DOM 树是一个以document为根节点的多叉树。因此解析器首先会创建一个document对象。标记生成器会把每个标记的信息发送给建树器。建树器接收到相应的标记时,会创建对应的 DOM 对象。创建这个DOM对象后会做两件事情:
- 将
DOM对象加入 DOM 树中。 - 将对应标记压入存放开放(与
闭合标签意思对应)元素的栈中。
还是拿下面这个例子说:
<html>
<body>
Hello sanyuan
</body>
</html>
2
3
4
5
首先,状态为初始化状态。
接收到标记生成器传来的html标签,这时候状态变为before html状态。同时创建一个HTMLHtmlElement的 DOM 元素, 将其加到document根对象上,并进行压栈操作。
接着状态自动变为before head, 此时从标记生成器那边传来body,表示并没有head, 这时候建树器会自动创建一个HTMLHeadElement并将其加入到DOM树中。
现在进入到in head状态, 然后直接跳到after head。
现在标记生成器传来了body标记,创建HTMLBodyElement, 插入到DOM树中,同时压入开放标记栈。
接着状态变为in body,然后来接收后面一系列的字符: Hello sanyuan。接收到第一个字符的时候,会创建一个Text节点并把字符插入其中,然后把Text节点插入到 DOM 树中body元素的下面。随着不断接收后面的字符,这些字符会附在Text节点上。
现在,标记生成器传过来一个body的结束标记,进入到after body状态。
标记生成器最后传过来一个html的结束标记, 进入到after after body的状态,表示解析过程到此结束。
# 容错机制
讲到HTML5规范,就不得不说它强大的宽容策略, 容错能力非常强,虽然大家褒贬不一,不过我想作为一名资深的前端工程师,有必要知道HTML Parser在容错方面做了哪些事情。
接下来是 WebKit 中一些经典的容错示例,发现有其他的也欢迎来补充。
- 使用</br>而不是<br>
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
2
3
4
全部换为<br>的形式。
- 表格离散
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
2
3
4
5
6
WebKit会自动转换为:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
2
3
4
5
6
- 表单元素嵌套
这时候直接忽略里面的form。
# 样式计算
关于CSS样式,它的来源一般是三种:
- link标签引用
- style标签中的样式
- 元素的内嵌style属性
# 格式化样式表
首先,浏览器是无法直接识别 CSS 样式文本的,因此渲染引擎接收到 CSS 文本之后第一件事情就是将其转化为一个结构化的对象,即styleSheets。
这个格式化的过程过于复杂,而且对于不同的浏览器会有不同的优化策略,这里就不展开了。
在浏览器控制台能够通过document.styleSheets来查看这个最终的结构。当然,这个结构包含了以上三种CSS来源,为后面的样式操作提供了基础。
# 标准化样式属性
有一些 CSS 样式的数值并不容易被渲染引擎所理解,因此需要在计算样式之前将它们标准化,如em->px,red->#ff0000,bold->700等等。
# 计算每个节点的具体样式
样式已经被格式化和标准化,接下来就可以计算每个节点的具体样式信息了。
其实计算的方式也并不复杂,主要就是两个规则: 继承和层叠。
每个子节点都会默认继承父节点的样式属性,如果父节点中没有找到,就会采用浏览器默认样式,也叫UserAgent样式。这就是继承规则,非常容易理解。
然后是层叠规则,CSS 最大的特点在于它的层叠性,也就是最终的样式取决于各个属性共同作用的效果,甚至有很多诡异的层叠现象,看过《CSS世界》的同学应该对此深有体会,具体的层叠规则属于深入 CSS 语言的范畴,这里就不过多介绍了。
不过值得注意的是,在计算完样式之后,所有的样式值会被挂在到window.computedStyle当中,也就是可以通过JS来获取计算后的样式,非常方便。
# 生成布局树
现在已经生成了DOM树和DOM样式,接下来要做的就是通过浏览器的布局系统确定元素的位置,也就是要生成一棵布局树(Layout Tree)。
布局树生成的大致工作如下:
- 遍历生成的 DOM 树节点,并把他们添加到
布局树中。 - 计算布局树节点的坐标位置。
值得注意的是,这棵布局树值包含可见元素,对于 head标签和设置了display: none的元素,将不会被放入其中。
有人说首先会生成Render Tree,也就是渲染树,其实这还是 16 年之前的事情,现在 Chrome 团队已经做了大量的重构,已经没有生成Render Tree的过程了。而布局树的信息已经非常完善,完全拥有Render Tree的功能。
之所以不讲布局的细节,是因为它过于复杂,一一介绍会显得文章过于臃肿,不过大部分情况下我们只需要知道它所做的工作是什么即可,如果想深入其中的原理,知道它是如何来做的,我强烈推荐你去读一读人人FED团队的文章从Chrome源码看浏览器如何layout布局。
# 总结
梳理一下这一节的主要脉络: